

Simplifying data integration and processing, ensuring easy access to suitable tools for development tasks, and facilitating seamless integration of cutting-edge technologies into our solutions are all factors that enhance our productivity and make our work more enjoyable.
Teradata VantageCloud Lake, the complete cloud analytics and data platform for AI, is now integrated with Google Cloud. VantageCloud Lake is the most performant data engine for processing both structured and semi-structured data across any data landscape. It includes ClearScape Analytics™, a comprehensive set of tools for data processing and analytics. For those working within the Google ecosystem, this integration brings our powerful lakehouse closer to tools like Vertex AI, Google’s ML development environment, and enables more seamless experimentation with the Gemini family of large language models (LLMs).
As data professionals working on data pipelines, analytics, or artificial intelligence and machine learning (AI/ML) models, our main goal is to build solutions and tools that help our organizations to better serve customers. We work with data from many sources in different formats, often with inconsistencies. Our job is to pull it all together by cleaning and analyzing data and creating models. Taking the models we've developed and making sure they work well in production and can handle large-scale use isn’t easy.
Efficient pipelines in a unified and trusted data ecosystem
Everything starts and ends with data. For data engineers, VantageCloud Lake, designed to work with object storage, enables management of uncontrolled data growth, as it allows management of structured and semi-structured data stored with any cloud service provider (CSP) through the lakehouse environment.
This data can easily be processed and transformed to build the datasets that data scientists and analysts rely on to build models and analyses. These datasets remain in the secure environment of the lakehouse and, subject to networking policies and virtual private cloud (VPC) service controls of specific organizations, are accessible from Google’s tools, like Vertex AI.
VantageCloud Lake also enables dynamic management of compute resources for more efficient pipelines.
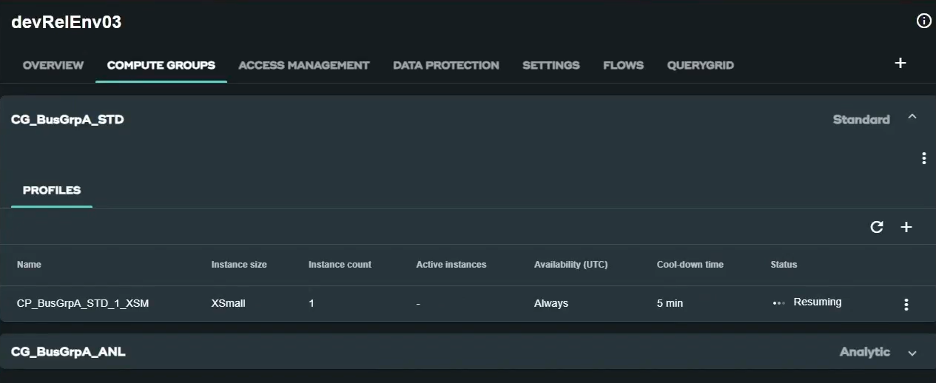
VantageCloud Lake compute groups management console
- Compute groups can be configured with different scheduled profiles, which can be suspended or resumed on command, or scheduled to manage ingestion and transformation pipelines and other heavy batch loads.
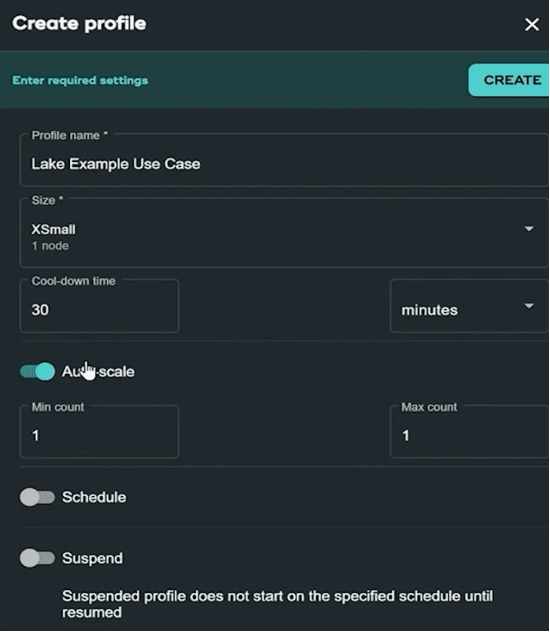
VantageCloud Lake compute profile management console
- Management of extract, load, and transform (ELT) pipelines is a breeze with VantageCloud Lake due to its integration with tools like Apache Airflow for workflow scheduling, Airbyte for data ingestion, and dbt for data transformations.
-employing-the-Teradata-connector.png?origin=fd)
Airflow Directed Acyclic Graph (DAG) employing the Teradata connector
Accelerated model development and deployment, plus easier lifecycle management
For data scientists, model development and deployment and lifecycle management is easier with VantageCloud Lake, thanks to ClearScape Analytics, Bring Your Own Model (BYOM) technology for model interchange management, and ModelOps for model lifecycle management. These tools can now be more easily integrated with Vertex AI and the Gemini family of LLMs.
ClearScape Analytics for end-to-end model development
- ClearScape Analytics is a comprehensive suite of analytics tools, featuring an extensive collection of in-database analytics functions tailored for AI/ML needs.
- Data exploration, data cleaning, feature engineering, and model training can be performed in database, significantly reducing compute costs through the VantageCloud Lake environment.
Data Exploration
Descriptive Statistics
td_columnsummary
td_categoricalsummary
td_univariatestatistics
td_getrowswithoutmissingvalues
td_whichmin
td_whichmax
td_histogram
td_qqnorm
Statistical Tests
td_anova
td_ztest
td_ftest
td_chisq
Path and Pattern
npath
attribution
sessionize
Text Analytics
td_textparser
ngramsplitter
td_wordembeddings
td_naivebayestextclassifiertrainer
naivebayestextclassifierpredict
td_sentimentextractor
td_ifidf
Data Preparation
Handling Outlier
td_getfutilecolumns
td_outlierfilterfit
td_outlierfiltertransform
td_oneclasssvm
td_oneclasssvmpredict
Handling Missing Values
td_getrowswithmissingvalues
td_simpleimputefit
td_simpleimputetransform
Parsing data
td_traintestsplit
td_convertto
td_numapply
td_strapply
td_fillrowid
td_roundcolumns
antiselect
pack
unpack
stringsimilarity
td_unpivoting
td_pivoting
Feature Engineering
Categorical Variable Transform
td_ordinalencodingfit
td_ordinalencodingtransform
td_onehotencodingfit
td_onehotencodingtransform
Continuous Variable Transform
td_nonlinearcombinefit
td_nonlinearcombinetransform
td_scalefit
td_scaletransform
td_functionfit
td_functiontransform
td_polynomialfeaturefit
td_polynomialfeaturetransform
td_rownormalizefit
td_rownormalizetransform
td_bincodefit
td_bincodetransform
movingaverage
Dimensionality Reduction
td_randomprojectionmincomponents
td_randomprojectionfit
td_randomprojectiontransform
Model Training And Forecasting
Model Training
td_glm
td_decisionforest
td_kmeans
td_svm
td_knn
td_xgboost
td_oneclasssvm
td_vectordistance
Model Evaluation And Selection
Model Scoring
td_glmpredict
td_kmeans predict
td_decisionforestpredict
td_svmpredict
td_xgboostpredict
td_oneclasssvmpredict
Model Evaluation
td_regressionevaluator
td_classificationevaluator
td_silhouette
td_roc
Machine learning (ML) functions
Vertex AI, Compute Engine, and BYOM
![]()
ClearScape Analytics in-database analytics functions, BYOM, and Vertex AI-powered AI/ML pipeline
- For ML techniques not available through in-database processing or requiring specialized compute, data preparation can still be performed in database, leveraging the VantageCloud Lake environment, while training can be deferred to Google tools like Vertex AI and Compute Engine
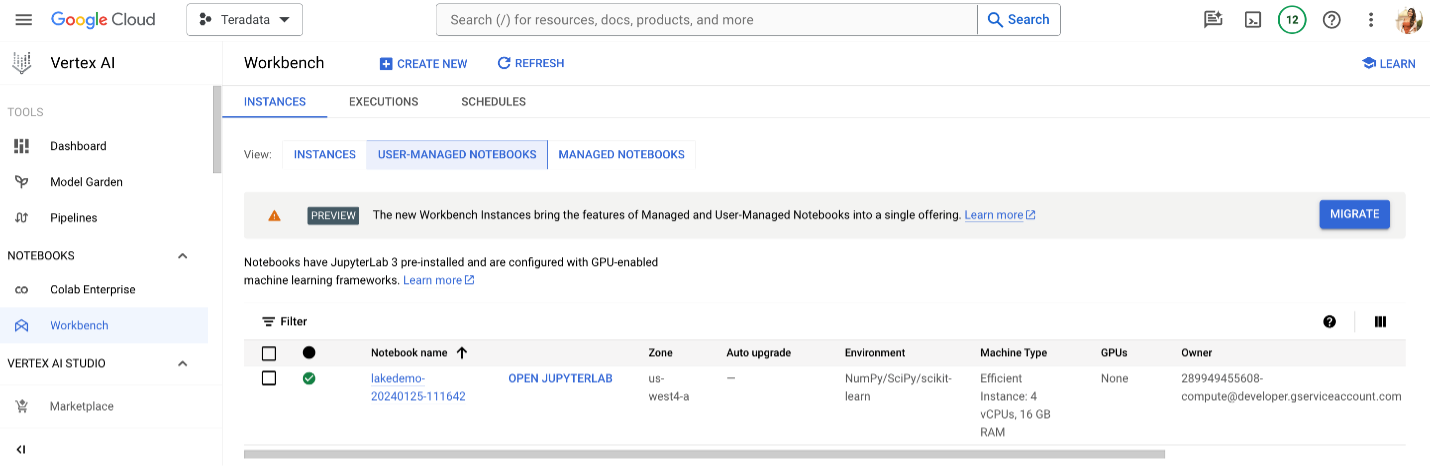
Teradata Jupyter extensions integrated with Vertex AI notebooks
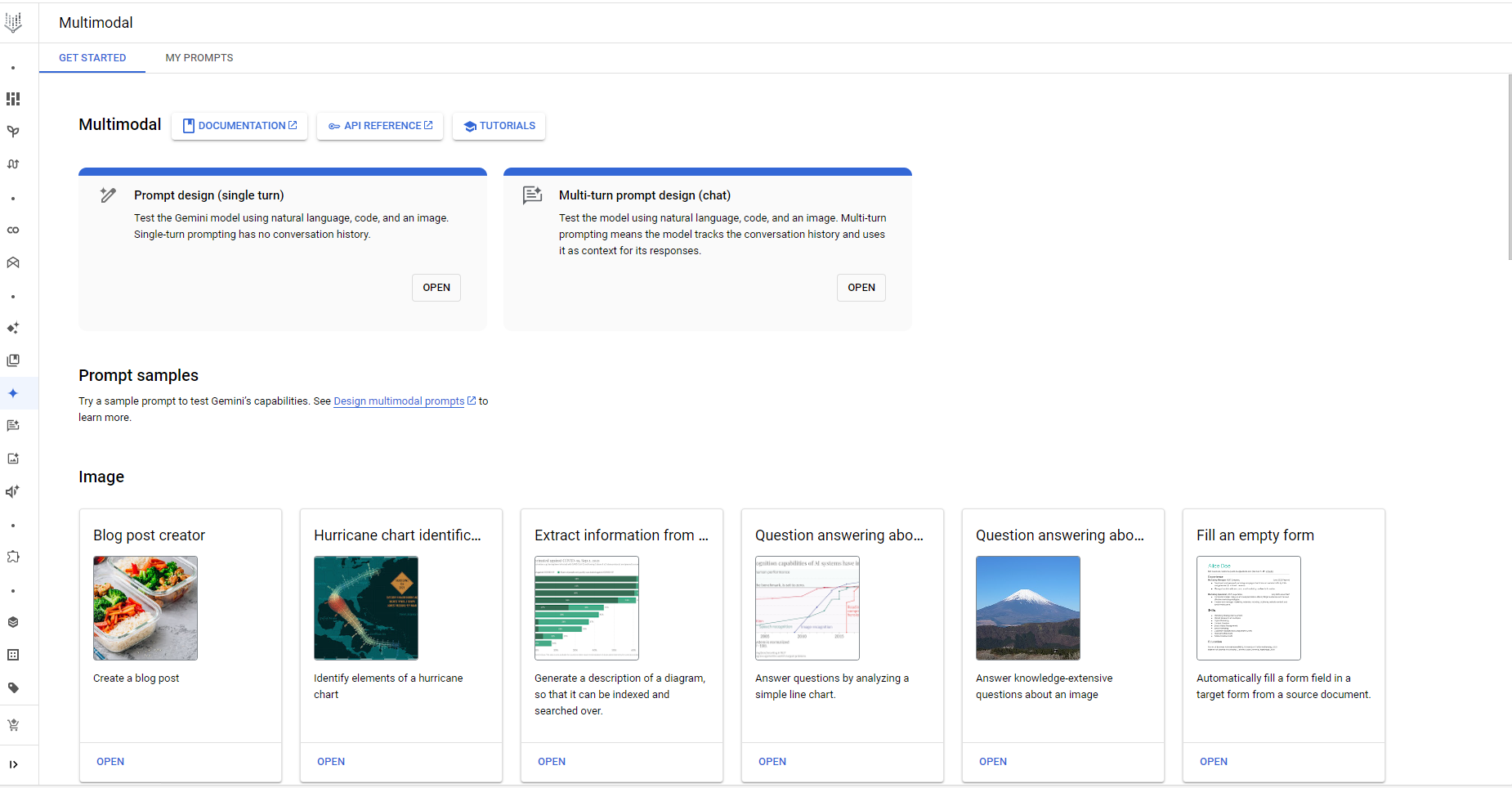
Gemini integrated with Vertex AI
- In these scenarios, models can be exported through PMML, ONNX, or other supported standards and deployed in database using BYOM technology.
- Models imported through BYOM can be used to easily score data in database, facilitating the use of models in production with the performance at scale of VantageCloud.
- Once models are deployed, their lifecycles can be tracked at scale with ModelOps technology. View the video below to learn more.
Experiment and innovate with generative AI
Google’s catalog of generative AI tools, such as the Gemini family of LLMs, are easy to integrate with data in your data lakehouse to deliver innovative solutions. For example, you can expedite customer service ticket resolution and improve customer service processes by leveraging LLMs for classification of tickets and analysis. View the demo to see it in action.
Conclusion
The integration of VantageCloud Lake with Google Cloud provides the trusted data foundation necessary for robust AI and analytics initiatives for data engineers, data scientists, and organizations in the Google Cloud ecosystem. Whether you’re a data engineer looking to streamline your pipelines or a data scientist aiming to maximize the efficiency of your ML models, VantageCloud Lake offers the tools and capabilities to meet your needs.
Learn more or request a demo of VantageCloud Lake on Google Cloud.
Feedback and questions
We value your insights and questions. Feel free to connect with me on LinkedIn and explore the wealth of helpful resources available on the Teradata Developer Portal, Teradata Developer Community, and Teradata YouTube.