 Kevin Bogusch
Kevin Bogusch
Connect Teradata Vantage with AWS Glue
Many Teradata customers are interested in integrating Teradata Vantage with AWS First Party Services. This newly updated Getting Started Guide can help.
Kevin Bogusch
 Wenjie Tehan
Wenjie Tehan
")
Many Teradata customers are interested in integrating Teradata Vantage Amazon Web Services (AWS) First Party Services. This guide will help you to connect Teradata Vantage to AWS Glue.
The procedure offered in this guide has been implemented and tested by Teradata. However, it is offered on an as-is basis. Amazon does not provide validation of Teradata Vantage using AWS Glue.
We encourage your feedback. We want to understand what you found useful, and how we can improve this guide. Please send your feedback to Shamira.Joshua@teradata.com and Wenjie.Tehan@teradata.com.
This guide includes content from both Amazon and Teradata product documentation.
Overview
This guide describes the procedure to migrate data from Teradata Vantage to Amazon S3 and from Amazon S3 to Teradata Vantage.
About AWS Glue
AWS Glue is serverless, and provides a fully managed ETL (extract, transform, and load) service that makes it easy for customers to prepare and load their data for analytics. AWS Glue consists of a central metadata repository known as the AWS Glue Data Catalog, an ETL engine that automatically generates Python or Sala code, and a flexible scheduler that handles dependency resolution, job monitoring and retries. We’ll be looking at the ETL functionality in this article.
AWS Glue natively supports Amazon Redshift and Amazon RDS (Amazon Aurora, MariaDB, Microsoft SQL Server, MySEL, Oracle and PostgreSQL). Teradata Vantage is not natively supported by AWS Glue, but data can still be imported into Amazon S3 using custom database connectors. The following figure shows how the data flows between Teradata Vantage and Amazon S3.

About Teradata Vantage
Vantage is the modern cloud platform that unifies data warehouses, data lakes, and analytics into a single connected ecosystem.
Vantage combines descriptive, predictive, prescriptive analytics, autonomous decision-making, ML functions, and visualization tools into a unified, integrated platform that uncovers real-time business intelligence at scale, no matter where the data resides.
Vantage enables companies to start small and elastically scale compute or storage, paying only for what they use, harnessing low-cost object stores and integrating their analytic workloads.
Vantage supports R, Python, Teradata Studio, and any other SQL-based tools. You can deploy Vantage across public clouds, on-premises, on optimized or commodity infrastructure, or as-a-service.
See the documentation for more information on Teradata Vantage.
Prerequisites
You should be familiar with AWS concepts and Teradata Vantage.
You will need the following accounts and systems:
- AWS account (you can create a free account)
- Security group that allows Glue to access Teradata Vantage
- S3 location of the JDBC driver (i.e. tdjdbc)
- S3 location to store Glue job script (i.e. tdglue/scripts)
- S3 location of the temporary directory (i.e. tdglue/temp)
- S3 location to store input data (i.e. tdglue/input)
- S3 location to store output data (i.e. tdglue/output)
- S3 VPC endpoint if you are accessing S3 from your VPC. See Amazon VPC Endpoints for Amazon S3 for more information.
- Teradata Vantage with the Advanced SQL Engine 17.0 or higher
Procedure
These are the steps to connect Teradata Vantage to AWS Glue.
- Download the Teradata Vantage driver
- Setup permissions
- Author a Glue Job (from Vantage to S3)
- Author a Glue Job (from S3 to Vantage)
Download the Teradata Vantage Driver
Download the latest Teradata JDBC Driver from here. Once you have the JDBC driver file, uncompress and upload the jar file to an AWS S3 bucket (i.e. tdjdbc) using the steps here.
Setup Permissions
This step creates the AWS IAM role that the ETL job in AWS Glue will use.
Create the IAM Role
From AWS Management Console, search for IAM.
On the IAM console, choose Roles in the left navigation pane.
Choose “Create Role”. The role type of trusted entity is “AWS service”.
Click on “Glue”.
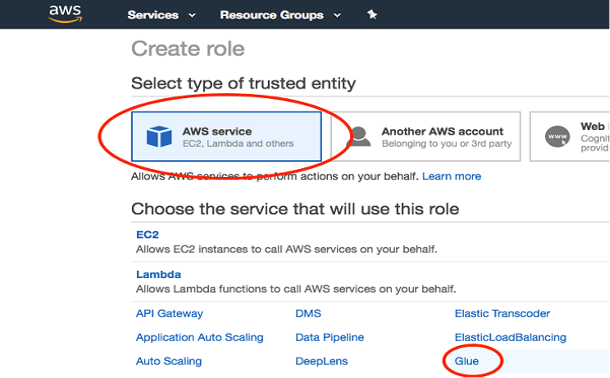-1.png?lang=en-US&origin=fd "Picture1-(27).png")
Choose “Next: Permissions”.
Search for the “AWSGlueServiceRole” policy, and select it.
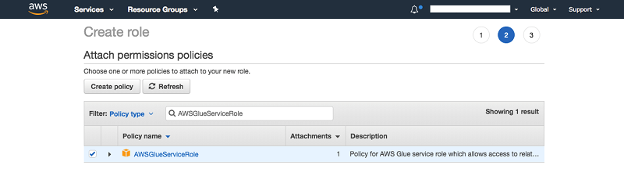-1.png?lang=en-US&origin=fd "Picture1-(28).png")
Search again for “AmazonS3FullAccess” policy, and select it.
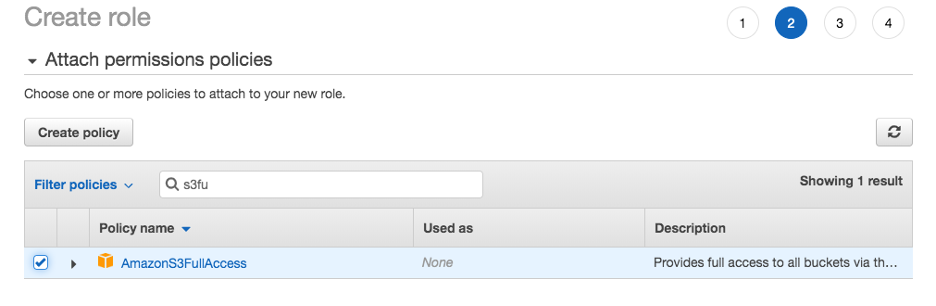-1.png?lang=en-US&origin=fd "Picture1-(29).png")
Search for “SecretsManagerReadWrite” policy, and select it.
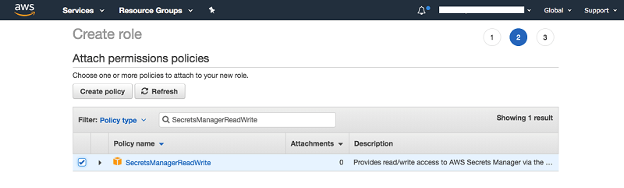-1.png?lang=en-US&origin=fd "Picture1-(30).png")
This policy is optional. You only need this policy if you are using “Secrets Manager” (see next section).
- Choose “Next: Tags”, add in the Key Value pair for tags if application.
Choose “Next:Review”.
Give your role a name (i.e. GluePermissions), and confirm all the policies you selected are there.
Choose “Create role”.
Setup Secrets Manager (optional)
Secrets Manager can be used to store credentials in a safe store. In this case, you can use Secrets Manager to store database information. This step is optional.
Open the console, and search for “Secrets Manager”.
In the AWS Secrets Manager console, choose “Store a new secret”.
Under Select a secret type, choose “Other type of secrets”.
In the “Secret key/value”, set one row for each of the following parameters:
- db_name
- db_username
- db_password
- db_url (jdbc:Teradata://<database instance private ip> i.e. jdbc:teradata://172.31.10.10)
- db_table
- driver_name (com.teradata.jdbc.TeraDriver)
- output_bucket: (i.e. s3://tdglue/output)
Choose “Next”.
For Secret name, use “TD_Vantage_Connection_Info”.
Choose “Next”.
Keep the “Disable automatic rotation” check box selected.
Choose “Next”.
Choose “Store”.
Author a Glue Job (Vantage to S3)
In this step, we will copy data from Teradata Vantage to an Amazon S3 bucket.
Add a JDBC Connection
Sign in to the AWS Management Console and open the AWS Glue console at https://console.aws.amazon.com/glue.
In the navigation pane, under Databases, choose Connections.
Choose Add connection and then complete the wizard.
Enter Connection name (i.e. tdConnection).
Select the connection type of JDBC. Click Next.
Enter the JDBC URL with the format of jdbc:protocol://host:port/databasename. For example: jdbc:teradata://<Vantage Instance Private IP>:1025/testDB.
Enter the Username and Password for your Vantage database.
Choose the VPC, Subnet and Security groups of your Vantage instance, click Next.
Review the information and click Finish
Create the Job
In the AWS Management Console, search for “AWS Glue”.
-1.png?lang=en-US&origin=fd "Picture1-(31).png")
In the navigation pane on the left, choose “Jobs” under the “ETL”.
Choose “Add job”.
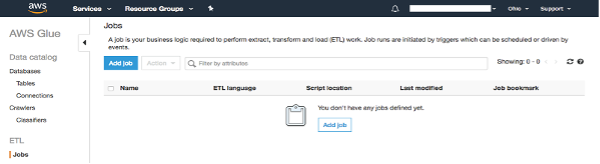-1.png?lang=en-US&origin=fd "Picture1-(32).png")
Give the job a name (i.e. td2s3).
Choose the IAM role that you created previously (i.e. GluePermissions).
For “Type” and “Glue version”, use “Spark” and the latest Spark and Python version.
For “This job runs”, choose “A new script to be authored by you”.
For “S3 path where the script is stored” and “Temporary directory”, choose the buckets or folders you created at Prerequisite step (i.e. tdglue/scripts and tdglue/temp).
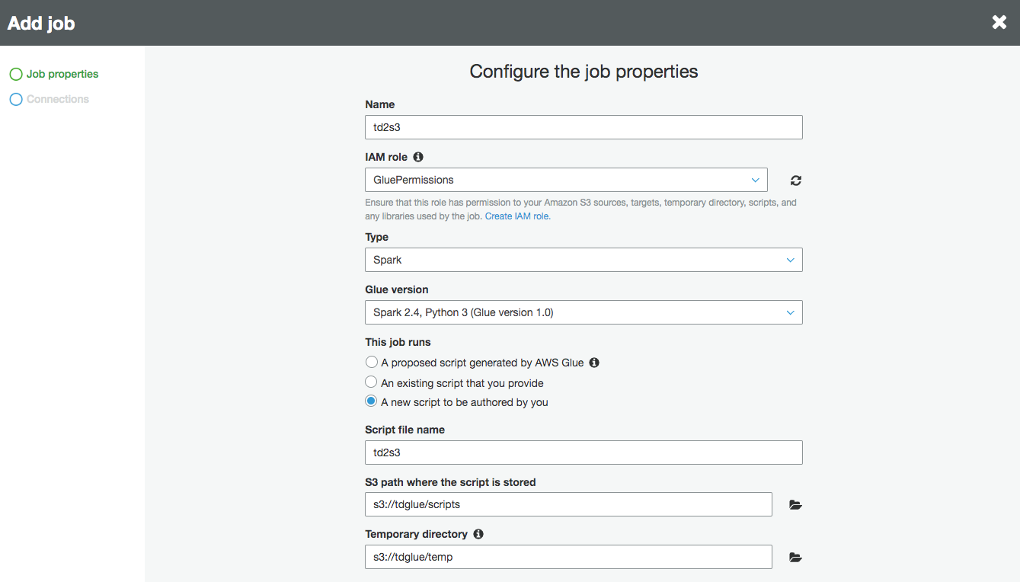-1.png?lang=en-US&origin=fd "Picture1-(33).png")
In the “Security configuration, script libraries and job parameters” section, choose the location of your JDBC driver (terajdbc4.jar) for “Dependent jars” path.
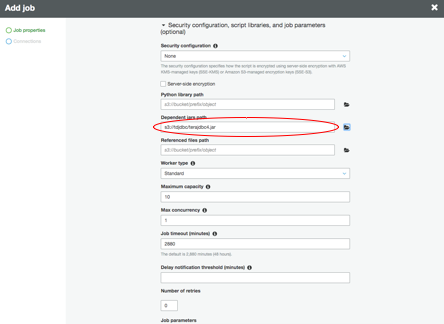-1.png?lang=en-US&origin=fd "Picture1-(34).png")
Choose “Next”.
On the Connections page, click Select on the connection you created earlier (i.e. tdConnection).
Choose “Save job and edit script”. This creates the job and opens the script editor.
-1.png?lang=en-US&origin=fd "Picture1-(35).png") In the editor, replace the existing code with following script. Note: region_name in the script should be replaced with the region where you created your secrets using Secrets Manager.
In the editor, replace the existing code with following script. Note: region_name in the script should be replaced with the region where you created your secrets using Secrets Manager.


Click on “Save” then click on “Run job”.
Job status can be monitored from Glue console. Once job is done, “Run status” would be marked as “Succeeded”.
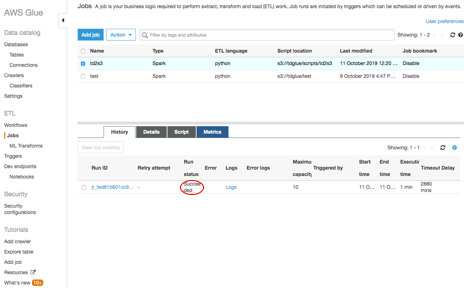-1.png?lang=en-US&origin=fd "Picture1-(36).png")
The output file will be kept at the S3 output bucket you set up before.
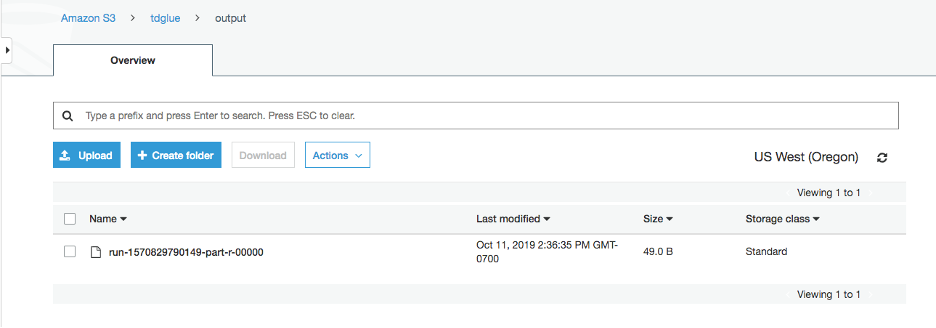-1.png?lang=en-US&origin=fd "Picture1-(37).png")
Author a Glue Job (S3 to Vantage)
In this step, we will copy data from an Amazon S3 bucket to Teradata Vantage.
Preparing data
In this step, we’ll create a Glue table using Crawler.
Upload your data file into a S3 bucket (i.e. tdglue/input).
In the AWS Management Console, search for “AWS Glue”.
-1.png?lang=en-US&origin=fd "Picture1-(38).png")
In the navigation pane on the left, choose “Databases”.
Click on “Add database”, give it a name, then click “Create”.
Click on “Tables” under “Databases” in the left navigation panel.
Click on the down arrow next to “Add tables” then choose “Add tables using a crawler”.
-1.png?lang=en-US&origin=fd "Picture1-(39).png") At “Add information about your crawler” window, give crawler a name and click on “Next”.
At “Add information about your crawler” window, give crawler a name and click on “Next”.
At “Specify crawler source type” window, select “Data stores” then click on “Next”.
At “Add a data store” window, use “S3” for “Choose a data store”, and put in the path where your data file is, then click on “Next”.
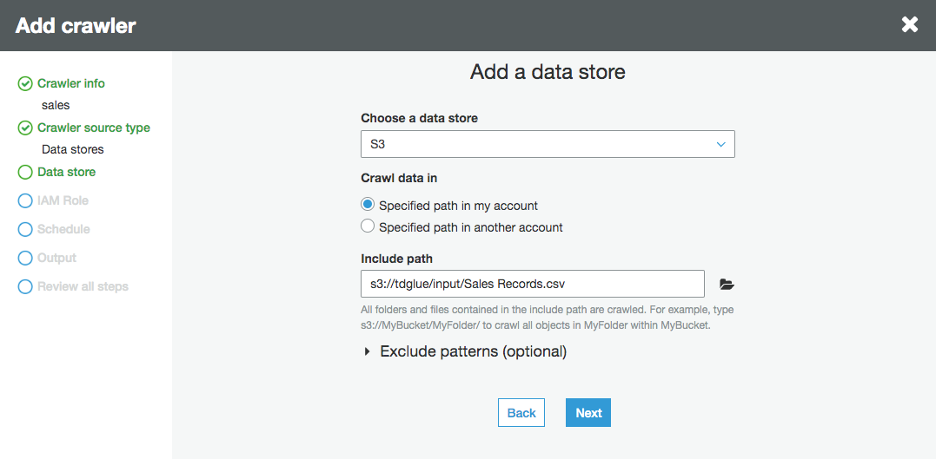-1.png?lang=en-US&origin=fd "Picture1-(40).png")
Choose “No” for “Add another data store”, then “Next”.
At “Choose an IAM role” window, pick “Choose an existing IAM role”, and use the role you created at the “Create the IAM role” step (i.e. GluePermissions), click on “Next”.
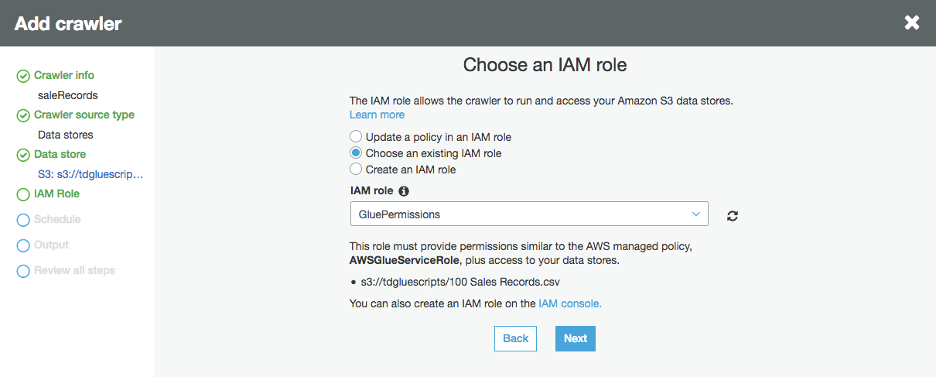-1.png?lang=en-US&origin=fd "Picture1-(41).png")
Use “Run on demand” as Frequency at “Create a schedule for this crawler” window, click on “Next”.
At “Configure the crawler’s output” window, choose the database you created earlier and click on “Next”.
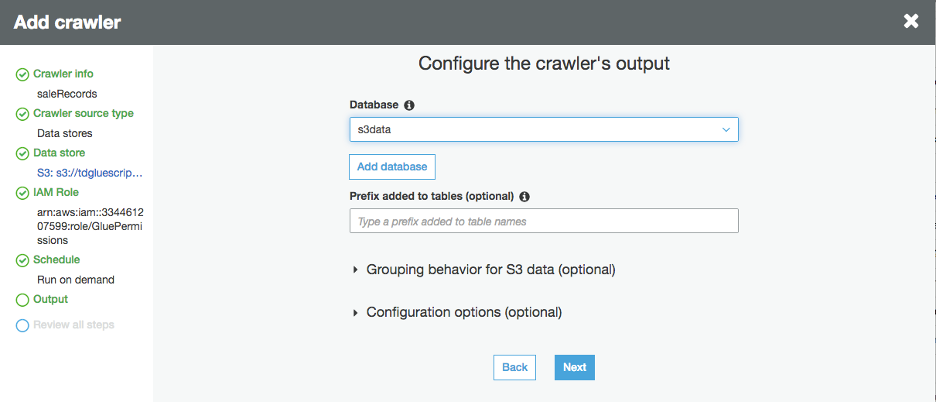-1.png?lang=en-US&origin=fd "Picture1-(42).png")
At the next window, review the information then click on “Finish”.
At the “Crawlers” window, click on “Run it now” to the question “Crawler <your crawler name> was created to run on demand. Run it now?”.
If you don’t see the question, choose the crawler you just created, then click “Run crawler”.
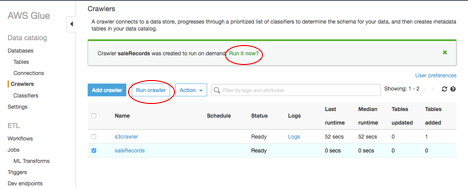-1.png?lang=en-US&origin=fd "Picture1-(43).png")
Once crawler is done, the status of the crawler becomes “Ready”, and a table will be created. It can be viewed by selecting “Tables” from left panel under the “Databases” you created earlier.
Add a job
If you are using Secrets Manager, go back to the Secrets Manager console, click on “TD_Vanatage_Connection_info”, select “Retrieve secret value” under “Secret value”, then click on “Edit”. Add two more keys: s3_database and s3_table. These two keys contain the database and table name you created using the crawler.
Skip this step if you are not using Secrets Manager.
In the navigation pane on the left, choose “Jobs” under the “ETL”.
Choose “Add job”.
-1.png?lang=en-US&origin=fd "Picture1-(44).png")
Give the job a name (i.e. s32td).
Choose the IAM role that you created previously (i.e. GluePermissions).
For “Type” and “Glue version”, use “Spark” and the latest Spark and Python version.
For “This job runs”, choose “A new script to be authored by you”.
For “S3 path where the script is stored” and “Temporary directory”, choose the buckets or folders you created at “Prerequisite” step (i.e. tdglue/scripts and tdglue/temp).
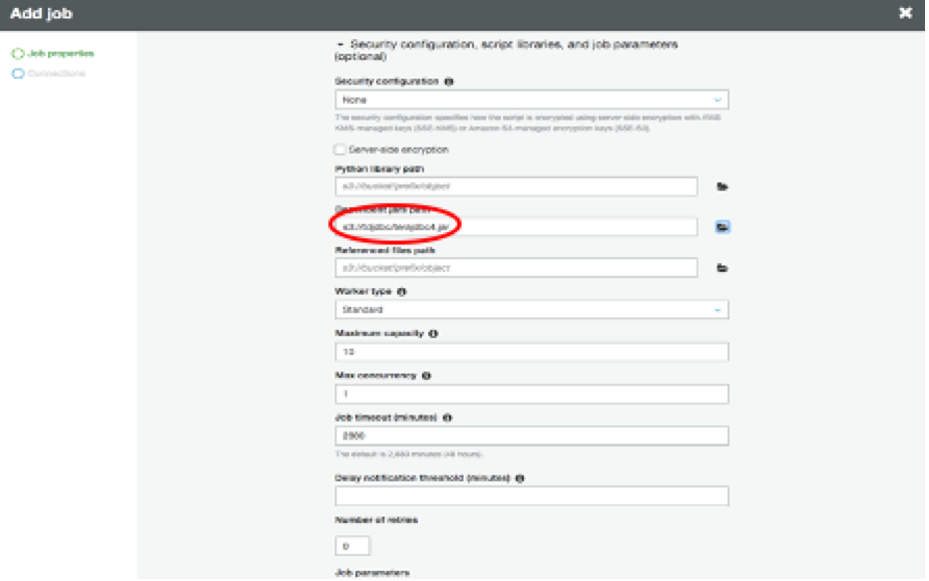
-1.png?lang=en-US&origin=fd "Picture1-(45).png") Expand the “Security configuration, script libraries and job parameters” section, choose the location of your JDBC driver (terajdbc4.jar) for “Dependent jars” path.
Expand the “Security configuration, script libraries and job parameters” section, choose the location of your JDBC driver (terajdbc4.jar) for “Dependent jars” path.
-1.png?lang=en-US&origin=fd "Picture1-(46).png")
Note: for better performance, change Worker type to G.1X (for memory-intensive jobs), or G.2X (for ML transforms), and increase Number of workers.
Choose Next.
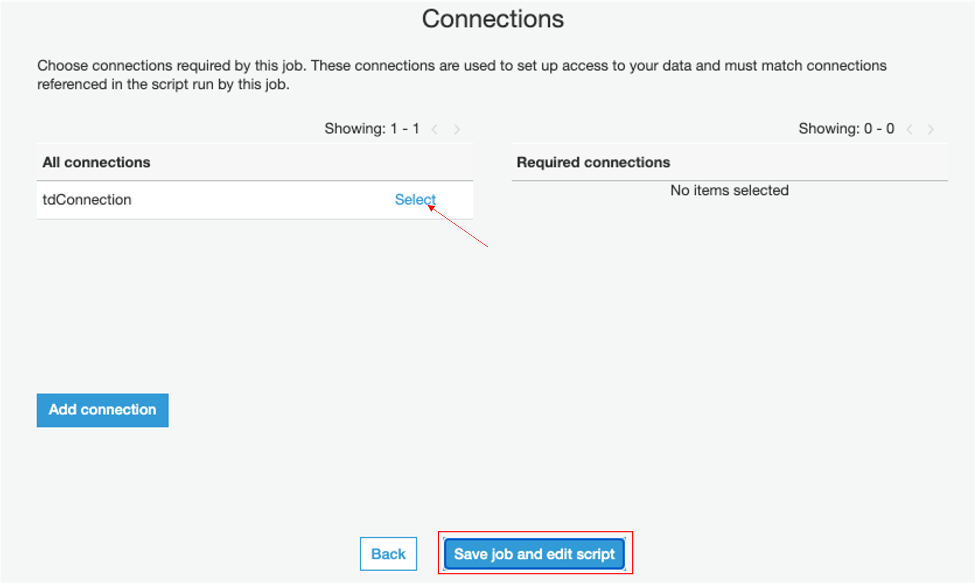
On the Connections page, click Select on the connection you created earlier (i.e. tdConnction). Choose Save job and edit script. This creates the job and opens the script editor.
-1.png?lang=en-US&origin=fd "Picture1-(47).png")
In the editor, replace the existing code with following script. Note: region_name in the script should be replaced with the region where you created your secrets using Secrets Manager.


Click on “Save” then click on “Run job”.
Note: connection_options “batchSize” and “TYPE” are optional. In this example “TYPE” is defined as “FASTLOAD”. This means JDBC FastLoad is used to improve performance. FASTLOAD can only be used when loading to an empty table.
Job status can be monitored from Glue console. Once job is done, “Run status” would be marked as “Succeeded”.
.png?origin=fd "Picture1-(48).png")
Bleiben Sie auf dem Laufenden
Abonnieren Sie den Blog von Teradata, um wöchentliche Einblicke zu erhalten